publications
Publication and Theses
2026
- arXiv
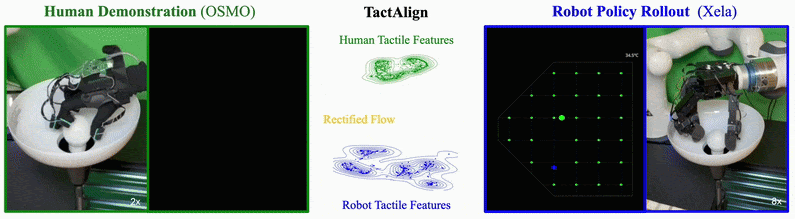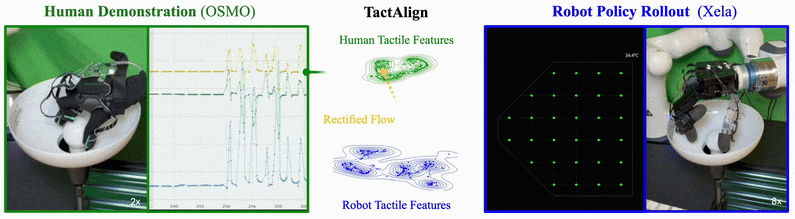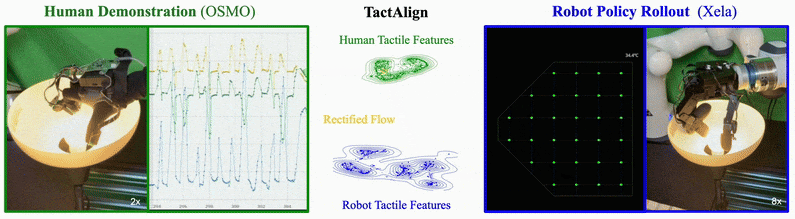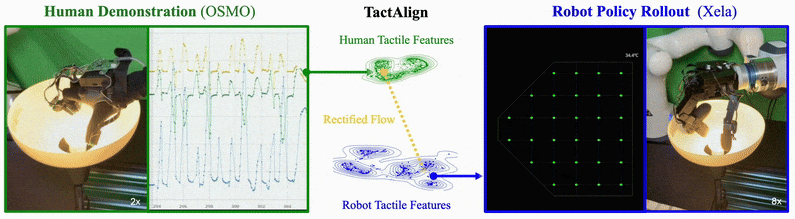 TactAlign: Human-to-Robot Policy Transfer via Tactile AlignmentYoungsun Wi , Jessica Yin, Elvis Xiang, Akash Sharma, Jitendra Malik, Mustafa Mukadam, Nima Fazeli, and Tess Hellebrekers2026
TactAlign: Human-to-Robot Policy Transfer via Tactile AlignmentYoungsun Wi , Jessica Yin, Elvis Xiang, Akash Sharma, Jitendra Malik, Mustafa Mukadam, Nima Fazeli, and Tess Hellebrekers2026TactAlign introduces a cross-sensor tactile alignment method enabling policy transfer from human demonstrators wearing wearable tactile devices to robots. Using rectified flow techniques, it transforms human and robot tactile observations into a shared latent representation without requiring paired datasets or manual labels. The approach demonstrates improvements across contact-rich manipulation tasks including pivoting, insertion, and lid closing, with successful generalization to unseen objects and zero-shot transfer for dexterous tasks using minimal human demonstration data.
- CVPR
 Any4D: Unified Feed-Forward Metric 4D ReconstructionJay Karhade, Nikhil Keetha, Yuchen Zhang, Tanisha Gupta, Akash Sharma, Sebastian Scherer, and Deva RamananIn Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, CVPR, 2026
Any4D: Unified Feed-Forward Metric 4D ReconstructionJay Karhade, Nikhil Keetha, Yuchen Zhang, Tanisha Gupta, Akash Sharma, Sebastian Scherer, and Deva RamananIn Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, CVPR, 2026Any4D is a scalable multi-view transformer for metric-scale, dense feed-forward 4D reconstruction. It generates per-pixel motion and geometry predictions across multiple frames, supporting additional modalities like RGB-D, IMU data, and Radar measurements. The approach uses modular scene representation with egocentric factors (depth and intrinsics) and allocentric factors (extrinsics and scene flow), achieving 2-3X lower error and 15X faster computation compared to baselines.
2025
- AINA | Dexterity from Smart Lenses: Multi-Fingered Robot Manipulation with In-the-Wild Human DemonstrationsIrmak Guzey, Haozhi Qi, Julen Urain, Changhao Wang , Jessica Yin, Krishna Bodduluri, Mike Lambeta, Lerrel Pinto, Akshara Rai, Jitendra Malik, Tingfan Wu, Akash Sharma, and Homanga Bharadhwaj2025
Learning multi-fingered robot policies from humans performing daily tasks in natural environments has long been a grand goal in the robotics community. Achieving this would mark significant progress toward generalizable robot manipulation in human environments, as it would reduce the reliance on labor-intensive robot interaction data collection. Despite substantial efforts, progress toward this goal has been bottle-necked by the embodiment gap between humans and robots, as well as by difficulties in extracting relevant contextual and motion cues that enable learning of autonomous policies from in-the-wild human videos. We claim that with simple yet sufficiently powerful hardware for obtaining human data and our proposed framework AINA, we are now one significant step closer to achieving this dream. AINA enables learning multi-fingered policies from data collected by anyone, anywhere, and in any environment using Aria Gen 2 glasses. These glasses are lightweight and portable, feature a high-resolution RGB camera, provide accurate on-board 3D head and hand poses, and offer a wide stereo view that can be leveraged for depth estimation of the scene. This setup enables the learning of 3D point-based policies for multi-fingered hands that are robust to background changes and can be deployed directly without requiring any robot data (including online corrections, reinforcement learning, or simulation).
- arXiv
 SPIDER: Scalable Physics-Informed Dexterous RetargetingChaoyi Pan, Changhao Wang, Haozhi Qi, Zixi Liu, Homanga Bharadhwaj, Akash Sharma, Tingfan Wu, Guanya Shi, Jitendra Malik, and Francois Hogan2025
SPIDER: Scalable Physics-Informed Dexterous RetargetingChaoyi Pan, Changhao Wang, Haozhi Qi, Zixi Liu, Homanga Bharadhwaj, Akash Sharma, Tingfan Wu, Guanya Shi, Jitendra Malik, and Francois Hogan2025Learning dexterous and agile policy for humanoid and dexterous hand control requires large-scale demonstrations, but collecting robot-specific data is prohibitively expensive. In contrast, abundant human motion data is readily available from motion capture, videos, and virtual reality. Due to the embodiment gap and missing dynamic information like force and torque, these demonstrations cannot be directly executed on robots. We propose Scalable Physics-Informed DExterous Retargeting (SPIDER), a physics-based retargeting framework to transform and augment kinematic-only human demonstrations to dynamically feasible robot trajectories at scale. Our key insight is that human demonstrations should provide global task structure and objective, while large-scale physics-based sampling with curriculum-style virtual contact guidance should refine trajectories to ensure dynamical feasibility and correct contact sequences. SPIDER scales across diverse 9 humanoid/dexterous hand embodiments and 6 datasets, improving success rates by 18% compared to standard sampling, while being 10× faster than reinforcement learning (RL) baselines, and enabling the generation of a 2.4M frames dynamic-feasible robot dataset for policy learning. By aligning human motion and robot feasibility at scale, SPIDER offers a general, embodiment-agnostic foundation for humanoid and dexterous hand control. As a universal retargeting method, SPIDER can work with diverse quality data, including single RGB camera video and can be applied to real robot deployment and other downstream learning methods like RL to enable efficient closed-loop policy learning.
- CoRL
 Tactile Beyond Pixels: Multisensory Touch Representations for Robot Manipulation (Sparsh-X)Carolina Higuera*, Akash Sharma*, Taosha Fan*, Chaithanya Krishna Bodduluri, Byron Boots, Michael Kaess, Mike Lambeta, Tingfan Wu, Zixi Liu , Francois Robert Hogan†, and Mustafa Mukadam†In 9th Annual Conference on Robot Learning, 2025
Tactile Beyond Pixels: Multisensory Touch Representations for Robot Manipulation (Sparsh-X)Carolina Higuera*, Akash Sharma*, Taosha Fan*, Chaithanya Krishna Bodduluri, Byron Boots, Michael Kaess, Mike Lambeta, Tingfan Wu, Zixi Liu , Francois Robert Hogan†, and Mustafa Mukadam†In 9th Annual Conference on Robot Learning, 2025Oral Presentation: \sim5-6% acceptance rate
We present Sparsh-X, the first multisensory touch representations across four tactile modalities: image, audio, motion, and pressure. Trained on 1M contact-rich interactions collected with the Digit 360 sensor, Sparsh-X captures complementary touch signals at diverse temporal and spatial scales. By leveraging self-supervised learning, Sparsh-X fuses these modalities into a unified representation that captures physical properties useful for robot manipulation tasks. We study how to effectively integrate real-world touch representations for both imitation learning and tactile adaptation of sim-trained policies, showing that Sparsh-X boosts policy success rates by 63% over an end-to-end model using tactile images and improves robustness by 90% in recovering object states from touch. Finally, we benchmark Sparsh-X ability to make inferences about physical properties, such as object-action identification, material-quantity estimation, and force estimation. Sparsh-X improves accuracy in characterizing physical properties by 48% compared to end-to-end approaches, demonstrating the advantages of multisensory pretraining for capturing features essential for dexterous manipulation.
- CoRL
 Self-supervised perception for tactile skin covered dexterous hands (Sparsh-skin)Akash Sharma, Carolina Higuera, Chaithanya Krishna Bodduluri, Zixi Liu, Taosha Fan, Tess Hellebrekers, Mike Lambeta, Byron Boots, Michael Kaess, Tingfan Wu , Francois Robert Hogan, and Mustafa MukadamIn 9th Annual Conference on Robot Learning, 2025
Self-supervised perception for tactile skin covered dexterous hands (Sparsh-skin)Akash Sharma, Carolina Higuera, Chaithanya Krishna Bodduluri, Zixi Liu, Taosha Fan, Tess Hellebrekers, Mike Lambeta, Byron Boots, Michael Kaess, Tingfan Wu , Francois Robert Hogan, and Mustafa MukadamIn 9th Annual Conference on Robot Learning, 2025We present Sparsh-skin, a pre-trained encoder for magnetic skin sensors distributed across the fingertips, phalanges, and palm of a dexterous robot hand. Magnetic tactile skins offer a flexible form factor for hand-wide coverage with fast response times, in contrast to vision-based tactile sensors that are restricted to the fingertips and limited by bandwidth. Full hand tactile perception is crucial for robot dexterity. However, a lack of general-purpose models, challenges with interpreting magnetic flux and calibration have limited the adoption of these sensors. Sparsh-skin, given a history of kinematic and tactile sensing across a hand, outputs a latent tactile embedding that can be used in any downstream task. The encoder is self-supervised via self-distillation on a variety of unlabeled hand-object interactions using an Allegro hand sensorized with Xela uSkin. In experiments across several benchmark tasks, from state estimation to policy learning, we find that pretrained Sparsh-skin representations are both sample efficient in learning downstream tasks and improve task performance by over 41% compared to prior work and over 56% compared to end-to-end learning.
- RSS
 DexterityGen: Foundation Controller for Unprecedented DexterityZhao-Heng Yin, Changhao Wang, Luis Pineda, Francois Hogan, Krishna Bodduluri, Akash Sharma, Patrick Lancaster, Ishita Prasad, Mrinal Kalakrishnan, Jitendra Malik, Mike Lambeta, Tingfan Wu, Pieter Abbeel, and Mustafa MukadamIn 21st Robotics: Science and Systems, 2025
DexterityGen: Foundation Controller for Unprecedented DexterityZhao-Heng Yin, Changhao Wang, Luis Pineda, Francois Hogan, Krishna Bodduluri, Akash Sharma, Patrick Lancaster, Ishita Prasad, Mrinal Kalakrishnan, Jitendra Malik, Mike Lambeta, Tingfan Wu, Pieter Abbeel, and Mustafa MukadamIn 21st Robotics: Science and Systems, 2025Teaching robots dexterous manipulation skills, such as tool use, presents a significant challenge. Current approaches can be broadly categorized into two strategies: human teleoperation (for imitation learning) and sim-to-real reinforcement learning. The first approach is difficult as it is hard for humans to produce safe and dexterous motions on a different embodiment without touch feedback. The second RL-based approach struggles with the domain gap and involves highly task-specific reward engineering on complex tasks. Our key insight is that RL is effective at learning low-level motion primitives, while humans excel at providing coarse motion commands for complex, long-horizon tasks. Therefore, the optimal solution might be a combination of both approaches. In this paper, we introduce DexterityGen (DexGen), which uses RL to pretrain large-scale dexterous motion primitives, such as in-hand rotation or translation. We then leverage this learned dataset to train a dexterous foundational controller. In the real world, we use human teleoperation as a prompt to the controller to produce highly dexterous behavior. We evaluate the effectiveness of DexGen in both simulation and real world, demonstrating that it is a general-purpose controller that can realize input dexterous manipulation commands and significantly improves stability by 10-100x measured as duration of holding objects across diverse tasks. Notably, with DexGen we demonstrate unprecedented dexterous skills including diverse object reorientation and dexterous tool use such as pen, syringe, and screwdriver for the first time.

2024
- CoRL
 Sparsh: Self-supervised touch representations for vision-based tactile sensingCarolina Higuera*, Akash Sharma*, Chaithanya Krishna Bodduluri, Taosha Fan, Mrinal Kalakrishnan, Michael Kaess, Byron Boots, Mike Lambeta, Tingfan Wu, and Mustafa MukadamIn 8th Annual Conference on Robot Learning, 2024
Sparsh: Self-supervised touch representations for vision-based tactile sensingCarolina Higuera*, Akash Sharma*, Chaithanya Krishna Bodduluri, Taosha Fan, Mrinal Kalakrishnan, Michael Kaess, Byron Boots, Mike Lambeta, Tingfan Wu, and Mustafa MukadamIn 8th Annual Conference on Robot Learning, 2024In this work, we introduce general purpose touch representations for the increasingly accessible class of vision-based tactile sensors. Such sensors have led to many recent advances in robot manipulation as they markedly complement vision, yet solutions today often rely on task and sensor specific handcrafted perception models. Collecting real data at scale with task centric ground truth labels, like contact forces and slip, is a challenge further compounded by sensors of various form factor differing in aspects like lighting and gel markings. To tackle this we turn to self-supervised learning (SSL) that has demonstrated remarkable performance in computer vision. We present Sparsh, a family of SSL models that can support various vision-based tactile sensors, alleviating the need for custom labels through pre-training on 460k+ tactile images with masking and self-distillation in pixel and latent spaces. We also build TacBench, to facilitate standardized benchmarking across sensors and models, comprising of six tasks ranging from comprehending tactile properties to enabling physical perception and manipulation planning. In evaluations, we find that SSL pre-training for touch representation outperforms task and sensor-specific end-to-end training by 95.1% on average over TacBench, and Sparsh (DINO) Sparsh (IJEPA) are the most competitive, indicating the merits of learning in latent space for tactile images.
2023
- Neural Radiance Field with LiDAR mapsIn Proceedings of the IEEE/CVF International Conference on Computer Vision, ICCV, Oct 2023
We address outdoor Neural Radiance Fields (NeRF) with LiDAR maps. Existing NeRF methods usually require specially collected hypersampled source views and do not perform well with the open source camera-LiDAR datasets - significantly limiting the approach’s practical utility. In this paper, we demonstrate an approach that allows for these datasets to be utilized for high quality neural renderings. Our design leverages 1) LiDAR sensors for strong 3D geometry priors that significantly improve the ray sampling locality, and 2) Conditional Adversarial Networks (cGANs) to recover image details since aggregating embeddings from imperfect LiDAR maps causes artifacts in the synthesized images. Our experiments show that while NeRF baselines produce either noisy or blurry results on Argoverse 2, the images synthesized by our system not only outperform baselines in image quality metrics under both clean and noisy conditions, but also obtain closer Detectron2 results to the ground truth images. Furthermore, to show the substantial applicability of our system, we demonstrate that our system can be used in data augmentation for training a pose regression network and multi-season view synthesis. Our dataset and code will be released.

2022
- Learned Depth Estimation of 3D Imaging Radar for Indoor MappingIn Proc. IEEE/RSJ Intl. Conf. on Intelligent Robots and Systems, IROS, Oct 2022
3D imaging radar offers robust perception capability through visually demanding environments due to the unique penetrative and reflective properties of millimeter waves (mmWave). Current approaches for 3D perception with imaging radar require knowledge of environment geometry, accumulation of data from multiple frames for perception, or access to between-frame motion. Imaging radar presents an additional difficulty due to the complexity of its data representation. To address these issues, and make imaging radar easier to use for downstream robotics tasks, we propose a learning-based method that regresses radar measurements into cylindrical depth maps using LiDAR supervision. Due to the limitation of the regression formulation, directions where the radar beam could not reach will still generate a valid depth. To address this issue, our method additionally learns a 3D filter to remove those pixels. Experiments show that our system generates visually accurate depth estimation. Furthermore, we confirm the overall ability to generalize in the indoor scene using the estimated depth for probabilistic occupancy mapping with ground truth trajectory.
2021
- Compositional and Scalable Object SLAMAkash Sharma, Wei Dong, and Michael KaessIn Proc. IEEE Intl. Conf. on Robotics and Automation, ICRA, May 2021
We present a fast, scalable, and accurate Simultaneous Localization and Mapping (SLAM) system that represents indoor scenes as a graph of objects. Leveraging the observation that artificial environments are structured and occupied by recognizable objects, we show that a compositional and scalable object mapping formulation is amenable to a robust SLAM solution for drift-free large-scale indoor reconstruction. To achieve this , we propose a novel semantically assisted data association strategy that results in unambiguous persistent object landmarks and a 2.5D compositional rendering method that enables reliable frame-to-model RGB-D tracking. Consequently, we deliver an optimized online implementation that can run at near frame rate with a single graphics card, and provide a comprehensive evaluation against state-of-the-art baselines. An open-source implementation will be provided at https://github.com/rpl-cmu/object-slam.
- M.S.
